
実験データベースBRIX LITEとチャットAIを組み合わせてみた
1. 背景
近年、急速な進化を遂げているチャットAI(LLM:Large Language Model)は、自然言語処理の分野で大きな注目を集め、様々な分野での活用が始まっています。
その中でも、**RAG (Retrieval-Augmented Generation)**と呼ばれる技術は、チャットAIの可能性をさらに広げると期待されています。RAGは、チャットAIが外部データソースから必要な情報を取得し、その情報を活用してより正確で詳細な回答を生成することを可能にする技術です。従来のチャットAIは、学習データに含まれる情報のみを基に回答していましたが、RAGを用いることで、最新のデータや専門的な知識にアクセスし、より質の高い回答を生成することができるようになります。
チャットAIは、データベースと接続することで、業務の効率化や新たな働き方を可能にする可能性を秘めています。
そこで、当社では実験データベースBRIX LITEとGoogleの最新チャットAIであるGemini 1.5 proを連携させ、どのようなことが可能なのか実験を行いました。
尚、Chat GPT 4oでも試しましたが、Gemini 1.5 Proの精度が最も高かったです。
2. 検証環境
LLMが作成したプログラムを手動でpythonにコピーして実行しました。
一般的なRAGとは異なる環境ですが、検証用として使うにはトライ&エラー&トレーニングがしやすい環境です。

<検証環境>
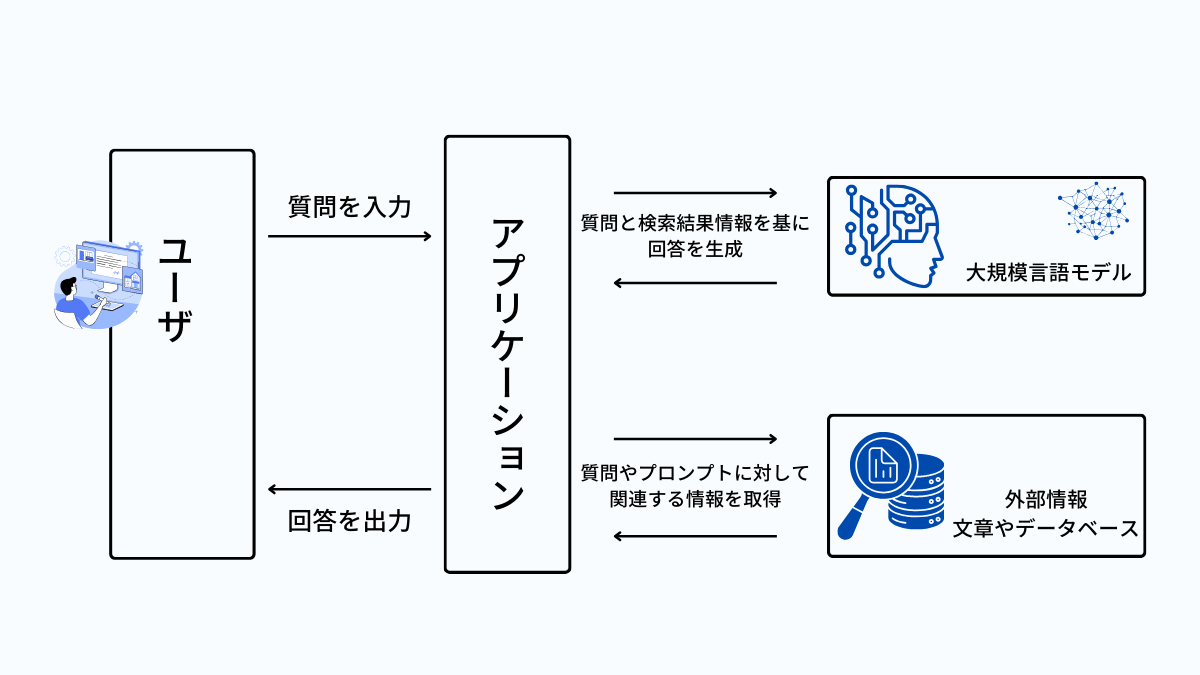
<一般的なRAG>
3. プロンプトトレーニング
まずは、実験データベースBRIX LITEをLLMに理解させるために、①APIの仕様と②データの格納方法をトレーニングしました。
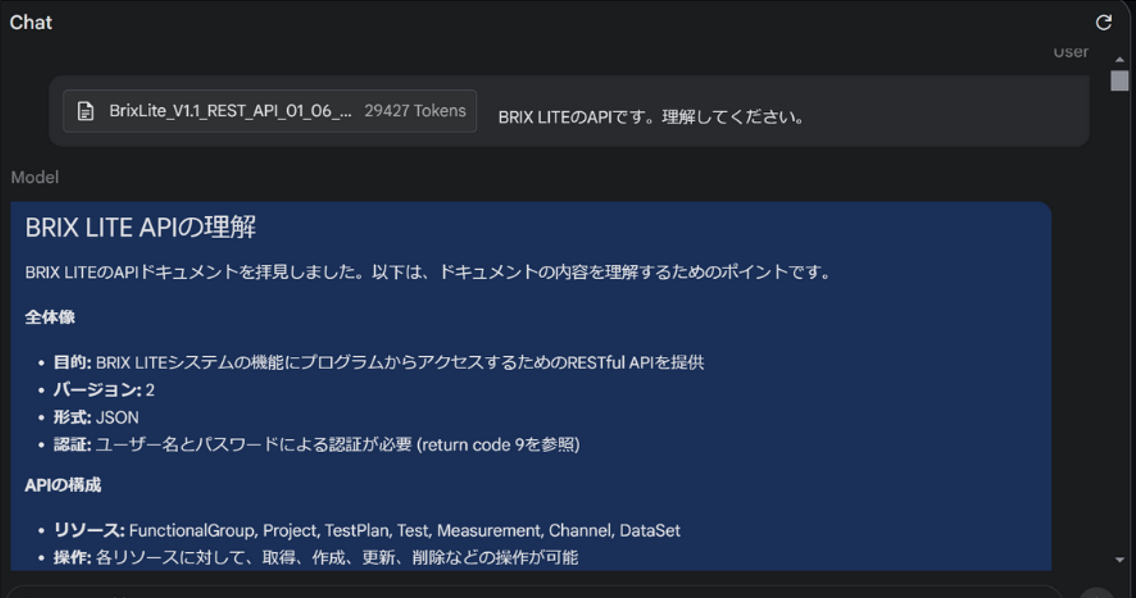
APIの仕様は、BRIX LITEのAPIドキュメントをLLMに読ませることで実現しました。トレーニングは、以下の図のようにAPIドキュメントファイルをアップロードし、「このドキュメントを理解してください」とLLMに依頼することで実施しました。
BRIX LITEのAPIドキュメントは、70ページにわたり、約50のREST APIコマンドが詳細に説明されています。このドキュメントを理解することで、データベースを外部から操作するプログラムを開発することが可能になります。

次に、BRIX LITEのデータの格納方法をトレーニングしました。
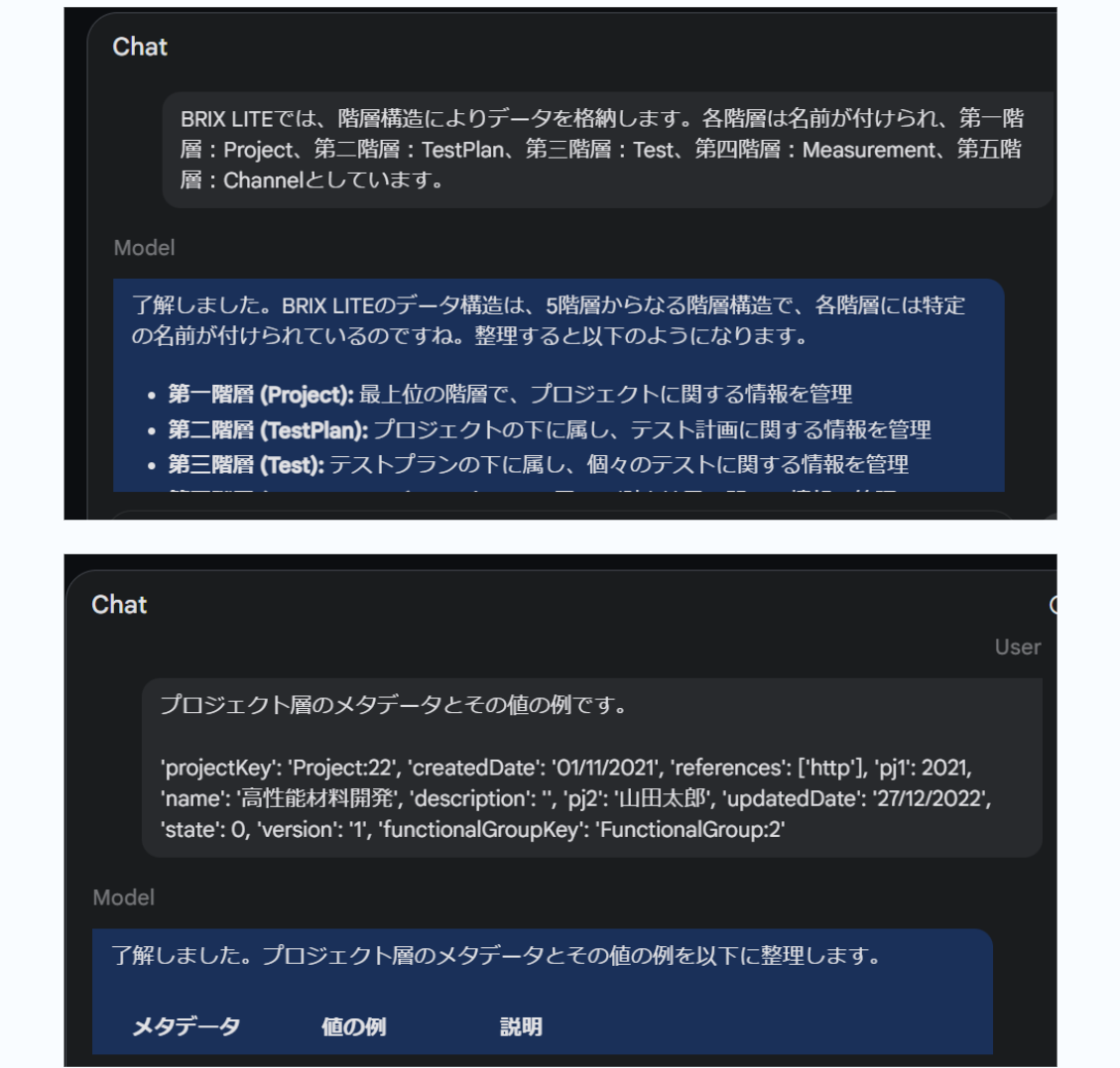
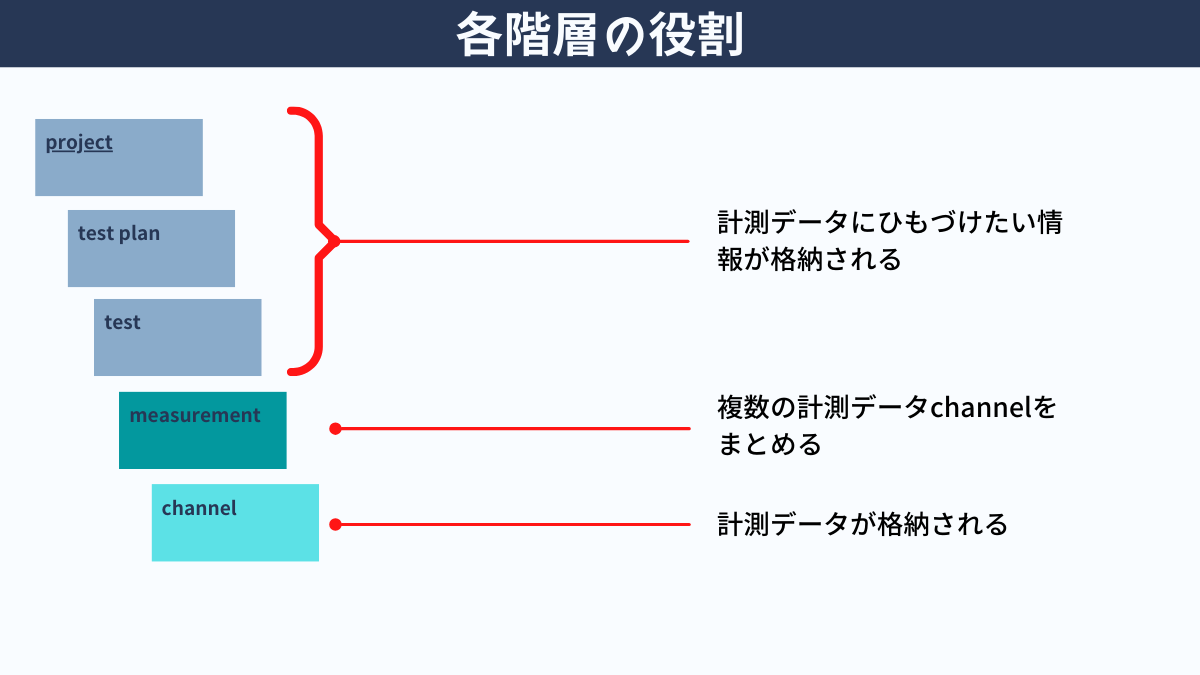
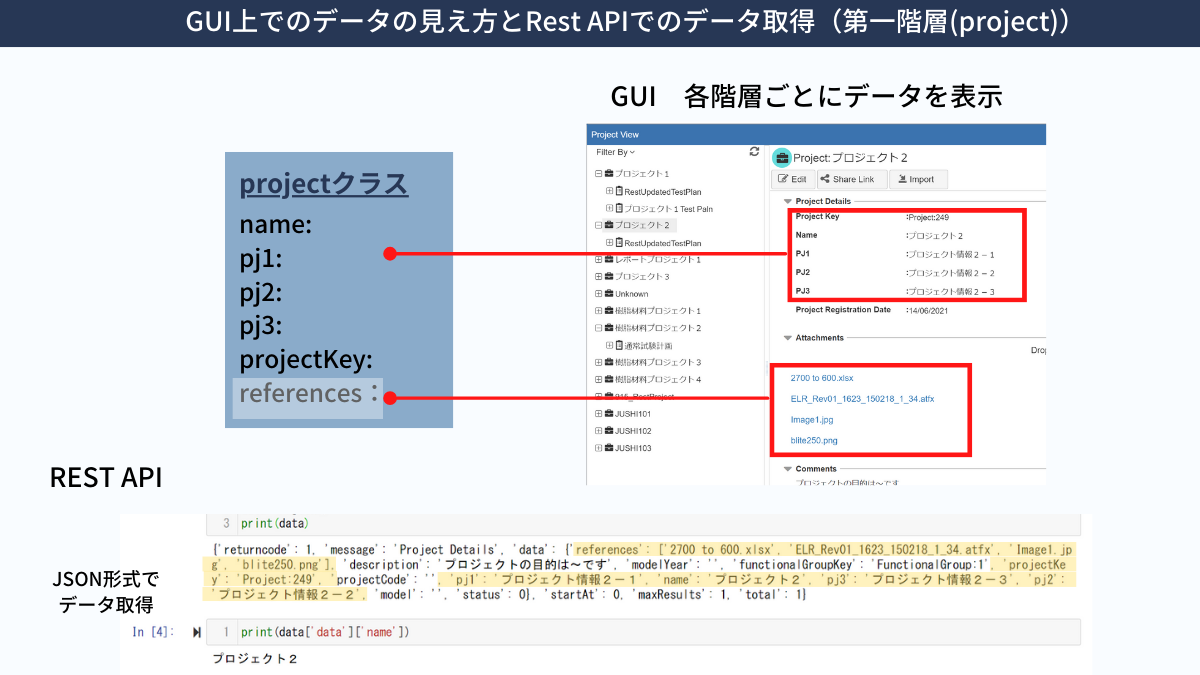
BRIX LITEでは、図にあるように階層構造でデータが格納されています。計測データは、Channel階層に格納されています。
① Project, Test Planなどの各層の名前をLLMに教え込みました。
② 各階層のデータは、APIを使って辞書型(キー、バリュー)のJSON形式で取得することができます。各層のデータの例をLLMに教え込みました。
トレーニングの結果、LLMは「それっぽい」合っているかのようなコードを生成できるようになりました。しかし、細かい仕様を完全に理解できていないため、細かな点で誤りがあり、精度の面で課題が残りました。

対策:
対策として、下記を実施しました。
具体的なAPI呼び出しの例を複数提示することで、LLMの理解を深めました。
LLMが生成したコードを検証し、エラーが発生した場合には、その原因を分析してフィードバックを提供しました。
結果:
このようなトライ&エラーによるトレーニングを繰り返すことで、LLMはある程度の依頼に対して正確に回答できるようになりました。
4. LLMによる実行例
ここでは、トレーニング済みのLLMがどのようなことを実行できたかを説明します。
当社が経験のある自動車実験や材料実験を念頭に置き、簡単なものから試していきました。
また、LLMが理解しやすいように、プログラムで使う言葉(例:プリント)などを意図的に使用してみました。
LLMの汎用化を目的とするのではなく、何ができるかを調べることを目的としました。
4-1. プロジェクトの計測名を答える
依頼: 「車両コードABC」プロジェクトの計測名を全てプリントしてください。
このケースでは、分岐の無いプロジェクトツリーに格納されたシンプルなデータを検索します。
一つのテスト(部品番号GHI)に一つの計測データ(性能試験)がついています。
LLMは、正しいコードを書いてデータベース内の計測名を答えてくれました。
次に、複雑なツリーに適応可能かを調べました。
依頼: 「PJ001」プロジェクトの計測名を全てプリントしてください。
このケースでは、複数の分岐があるプロジェクトツリーに格納された複雑なデータを検索します。
三つのテスト(ProtoType1~3)に、それぞれ6つの計測データ(Composition~TensileRaw)がついています。
つまり、合計3X6=18の計測データがついていますが、LLMは、正しいコードを書いてデータベース内の計測名を出力できました。

4-2. XYグラフを描く
依頼: 「車両コードABC」プロジェクトの計測データでXYグラフを作成してください。X軸は、エンジン回転数の計測データを使う。Y軸は、出力の計測データを使う。
このケースでは、BRIXデータベースに格納されたデータを使用してグラフを書きます。
さすがに、LLMは自動車実験の知識は無いので、何をX軸として、何をY軸とするかを依頼に書いています。
計測データの指定は、「車両コードABCプロジェクトの計測データ」と少し曖昧な表現で与えてみました。
具体的に書くのであれば、「プロジェクト「車両コードABCプロジェクト」、試験計画「エンジンコードDEF」、試験「部品番号GHI」の計測「性能試験」のデータ」となりますが、ここはLLMの理解力を試して曖昧な表現で依頼してみました。
結果、LLMはデータを正確に特定してグラフを作成しました。

また、この時のグラフタイトルは、私が指定しなかったのでLLMが判断して作成しています。
何回かこの事例を試しましたが、グラフタイトルのつけ方は毎回異なりました。
一番良かったのは、このデータが格納された計測名「計測名:性能試験」をグラフタイトルにつけてくれた時です。
次に、複雑なツリーに適応可能かを調べました。
複数の分岐があるプロジェクトツリーに格納された複雑なデータを検索し、XYグラフを作成します。
依頼: プロジェクト「PJ001」の計測「TensileRaw」のXYグラフを書いてください。X軸は「strain」、Y軸は「stress」としてください。グラフは、テスト毎に書いてください。
結果、この件もLLMはデータを正確に特定してグラフを作成しました。
3つのサンプルに対する歪試験のXYグラフを作成できました。

さらに、応用例として今回作成した3つのサンプルの歪試験のグラフを重ね書きを依頼してみました。
依頼: プロジェクト「PJ001」の計測「TensileRaw」のXYグラフを書いてください。X軸は「strain」、Y軸は「stress」としてください。テスト毎のデータを重ね書きしてください。
結果、この件もLLMは正しくグラフを作成しました。

5. まとめ
今回、LLMに実験データベースを教育し、様々なことを依頼しましたが、とても正確な解が得られました。
ひとまずは、エンジニアの良い助手くらいにはなりそうな期待が持てます。
他にもいろいろなことを試していきますが、今回は書ききれないので次回以降のブログで書いていこうと思います。
6. チャットUI
余談ですが、今回は、LLMが作成したプログラムを手動でpythonにコピーして実行しましたが、この動作をプログラムで実行することもできます。
また、ユーザーインターフェースとしてチャット画面を作成すると、ユーザからはプログラムを意識せずにあたかも人と話しているような操作性を実現することができます。
